Note: i built a webapp around an image captioning model as demoed later in the blog post. I wish I could release the app to allow others to try it but given the current closed nature of OpenAI GPT3 keys, the limitations on token usages for the private beta users, and the process one has to go through to release anything to public, for now I have decided to keep the app private.
Experimenting with GPT3 Part I - Image captioning
I was recently fortunate enough to get beta access to the much talked about OpenAI GPT3 generative language model API. In a short span of 5-6 months there’s already an incredible amount of online literature ranging from technical deep dives of the paper itself Language Models are Few Shot Learners to every possibly imagined test of text generation (e.g., gwern).
GPT3 TL;DR
“We have the most sophisticated natural language pre-trained model of its time”
- a16z podcast, July 2020
If you haven’t heard the news yet or seen the many videos across the internet, here’s a quick rundown:
- Another large-scale transformer language model (like BERT), just like, really really large
- The language generation is incredibly, incredibly good compared to previous SOTA, even without the typical model fine tuning. There have been many examples of humans unable to discern whether the text was AI generated. Its performance is fairly task agnostic (and performs across the usual NLP benchmarks tasks) especially in few-shot settings. This is ever closer to the way we think about how humans learn and process language, and spectres of AGI
- It’s a product of enormous compute (175B params model), and basically impossible to retrain outside of highly sophisticated tech companies today without investing millions. It’s so expensive to train and the upfront investment is so great that OpenAI is turning this into a commercial product.
- What GPT is not good at (relatively): Common sense questions (e.g., “if I put cheese in the fridge, will it melt?”), Bidirectional tasks (e.g., fill in the blank), Still racist/sexist/biased (OpenAI interestingly had an entire section dedicated to this)
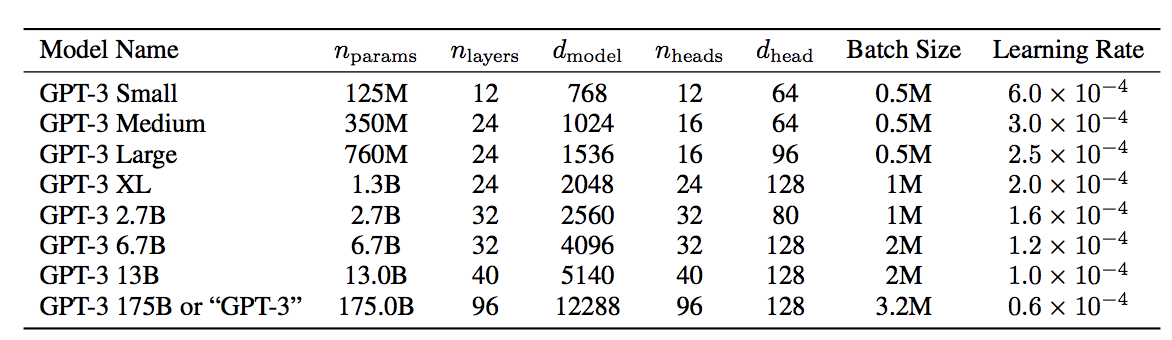
The largest GPT3 model was trained with a 175B params model
Beyond language in and language out

Example of a GPT3 generated passage that humans had difficulty distinguishing
From reading the paper results (and any cursory test of the API itself), it’s easy to see that the model performs well in a variety of tasks whereby you plainly feed it text, and likewise output text. The paper tests a variety of common NLP benchmark tasks, flexing on both fine-tuned, tasks specific SOTA models and human beings (apparently college students on average are not too great at SAT analogies).
Similarly, for the past 4 months hobbyists have extensively tinkered, and companies have been made, from experimenting with applications of plain text generation, often in a creative context (e.g., AI Dungeon). VC-raising startups have been made around text summarization and generation. Someone tried to get GPT3 to tell them the meaning of life and the universe.
However, some people have found more interesting applications of outputting text through GPT3 that ends in a output that’s something else:
- Web layouts in JSX code - here is one of the first instances of someone demonstrating code generation, I presume simply from providing a few examples and asking the engine.
- Figma layout - this is a similar, and clever idea of not generating code per se, but knowing that Figma layouts are represented in JSON to be built through the Figma Plugins, and leveraging GPT3s incredible pattern matching ability to force it to output JSON given a natural language input. The flow according to the author is: raw text → OpenAI API + GPT-3 → return a structured JSON response (representation of the Figma canvas) → Figma plugin code
This idea of raw text → GPT-3 → some structured data → some tool that builds from the structured data seems like an incredible concept with amazing potential.
Image as an input
“[A limitation of GPT3 today is that] large language models not grounded in other domains of experience, such as video or real-world physical interaction, and thus lack a large amount of context about the world…”
- Language Models are Few-Shot Learners, 2020
Likewise, there have been experiments where the input into GPT3 itself was sourced from beyond text, but I haven’t found many great examples outside of voice to text, for example: Podcast with GPT3 - this is honestly a little gimmicky but it in a way you can think of the flow as voice → text to voice api → gpt3 api → voice to text
Naturally, this led me into thinking about how to incorporate images as an input - how could we give “vision” to a “blind” model? I came across a GPT2 project whereby someone translated training data image pixels into text representation, trained the model to recognize this structured data format, and generated new Pokemon sprites. Unfortunately the GPT3 model is not open sourced like GPT2, and as of yet, there is no way to tune a custom dataset to such a custom representation of images. Ok then, what if I somehow describe what is in the image, and use GPT3 to build on top of that description?

Examples from a popular image captioning training dataset
There is an entire body of literature and research on image captioning and other cross-model representation related to vision + language tasks, though even SOTA today seems to be a bit hit or miss. Just for the sake of having a quick working model I decided to spin up an existing repo of Self-critical Sequence Training for Image Captioning, CVPR17 though at the time of writing much more modern, transformer based models exist such as Microsoft OSCAR (Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks).
Captioning workflow
The approach is fairly straightforward: feed into GPT what the captioning model outputs. Presumably GPT will take a plain description, and add some flair, depending on the seeded prompt. A couple of quick notes:
- I will be tuning this some more in the future but for now this is done zero-shot. GPT3 was not given any additional examples in the prompt itself
- I tried asking for many types of sentiments (funny, angry, happy etc.) but for some reason “sad” seemed to generate the best and funniest comments.

Illustrative flow of image through the captioning app
Demo video
I mocked up a quick web app to demonstrate a simple captioning engine. As seen from the demo, some examples worked better than others.
Additional examples
Here are a few additional images I ran through the app.

“They all face a huge problem, they don’t have balls”

“The woman is outraged that so many people are facing starvation while she can afford this luxury”

“It wasn’t even worth it”

“A young man sits in the dark bedroom of his autistic brother, who is sitting up and staring apprehensively at the computer”

“She knew that it would be her last surfing adventure”
Some closing thoughts
“[GPT3] is entertaining, and perhaps mildly useful as a creative help, but trying to build intelligent machines by scaling up language models is like building high-altitude airplanes to go to the moon. You might beat altitude records, but going to the moon will require a completely different approach.”
- Yann LeCunn
From my couple weeks of experimentation, it does seem like GPT3’s primary source of power is scale, a result of compiling the largest corpus of text, into the largest, most complex neural net. Fundamentally it’s unclear how much “logic” in a plain human-like sense, the model has actually retained. The idea of translating text into structured data for build purposes is a prime example to test the models capabilities (e.g., can you logically write code, do math, do X task that requires more than just pattern matching from a large set of examples?). It will be interesting to see where people take this notion, and hopefully I’ll get to do some more experimentation in a part II.
Special thanks:
- OpenAI for giving a random like me access to their amazing product
- ruotianluo’s unofficial Pytorch implementation for Self-critical Sequence Training for Image Captioning