Generative Art with CPPN-GANs Part II
In the previous blog post I attempted to train a vanilla GAN with a CPPN-architecture and failed to find convergence, and in this post I reattempt generation using instead, a Wasserstein GAN, on a few different datasets. Code for the new CPPN-WGAN-GP can be found here.

Wasserstein GANs
GANs are hard to train, for a variety of reasons. First, in the world of personifying neural nets, to repeat the oft-used analogy, the art forger always seems to have a harder job than the art critic; GAN balancing naturally becomes this black art of preventing the discriminator from overpowering the generator. Behind this simple, intuitive picture, lies a host of problems in the mathematical theory behind the architectures, which further explains exploding/vanishing gradients, mode collapse, and other not-so-fun issues.
Inherently, the problem of generative modelling is one of comparing, and mimicking probability distributions. How do we artificially create a function with neural nets, that emits the same densities as the true distribution of the training data? Backpropagation dictates then, that our loss function reflect our objective - this thus has led to the prevalence of metrics such as the Kullbeck-Leibler Divergence (e.g. in vanilla VAEs), Jenson-Shannon Divergence (e.g. indirectly, in vanilla GANs), and Total Variation Distance. Likewise, the WGAN proposes the Wasserstein metric, or often known as the “Earth-Mover’s distance”.
I won’t go into the mathematical details (you can find a great blog post here), but in summary the paper explains that the Wasserstein metric (and using the metric as a loss function for a GAN) is important because:
- There are many distributions out there that will converge under EM, but not under KL, reverse KL, TV, and JS divergences.
- Compared to other divergences, and under assumptions reasonable in a GAN model, only the EM is continuous everywhere, and differentiable almost everywhere, which is extremely important for backpropagation.
- Under assumptions reasonable in a GAN model, every distribution that converges in the other divergences will also converge with EM.
- In vanilla GANs you need to alternate training the discriminator and generator, but in WGANs on each iteration you can train the discriminator to convergence (which gives you the accurate distance metric and loss function \(W(P_r, P_{\theta})\), and then train the generator.
- Does a bunch of mathematical manipulations to make this loss function tractable, and usable for training.
- Unlike the Vanilla GAN which has no quantitative metric for evaluating results, the Wasserstein distance is a direct (or at least well correlated) metric of sample quality!
Shortly after the WGAN paper was released, a few researchers tweaked the algorithm to improve WGAN training, referred to as WGAN with Gradient Penalty (WGAN-GP). In this project I apply the WGAN-GP variation to three datasets: MNIST, CIFAR10, and CASIA.
MNIST
MNIST converged, unlike the vanilla GAN architecture, after a few hours of training, and the Wasserstein distance does seem to indeed correspond with image quality.
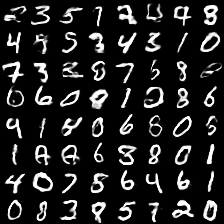
Enlarged images (500x500):
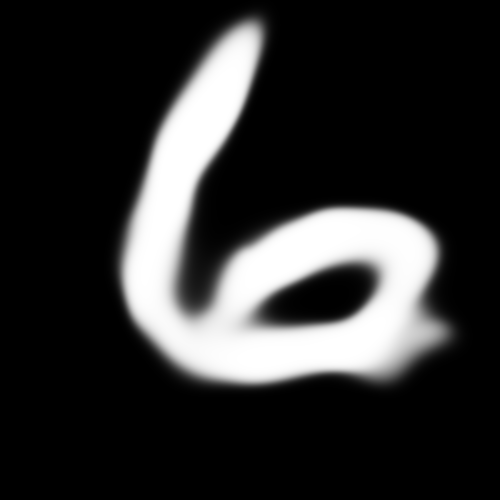

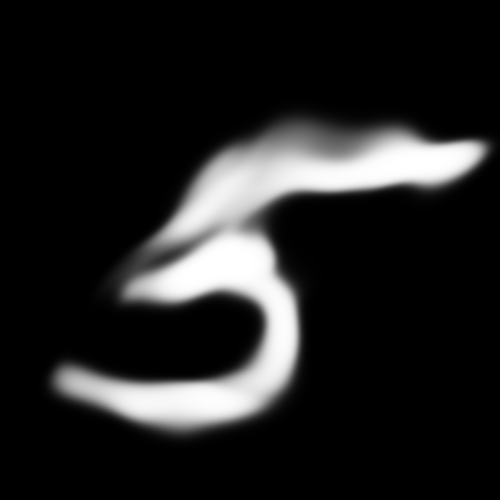
Interpolation:

However, blowing the images up yielding very different results than that of the Vanilla-GAN. The images had a much smokier and blurrier quality than the sharp pictures from the GAN. Its unclear to me why this is the result from using the Wasserstein objective as compared to the JS Divergence. This result is similar to David Ha’s CPPN-GAN-VAE, which he hypothesizes that the blurriness is caused by using the Maximum Likelihood objective in the VAE, yet this model does not.
CIFAR10
I thought the natural extension would be an attempt to train this model on colored images. Unfortunately, Cifar 10 was unable to converge into any meaningful resemblance of the original dataset, and after a few hours of training the Wasserstein distance was unable to continue decreasing. Nonetheless, the images generated were still interesting, colorful, and resembled the original CPPN color generations.

Enlarged images:


Interpolation:
CASIA
I’ve always wanted to mess with the Casia Chinese Handwriting dataset. A couple of user notes for anyone who’s considering using this in the future. This dataset was developed by the Chinese Academy of Sciences, Institute of Automation, and comes in filesizes of at least a couple hundred MB. This is only a subset of their entire dataset, whereby the full data can only be obtained through a manual request form. Even so, their data takes exceedingly long to download due to the location/infrastructure of their servers, and comes in forms that require some preprocessing. @lucaskjaero’s pycasia library is a good starting point for managing this data.
I scaled this dataset to 64x64, and trained for around 16 hours, obtaining reasonable results. Unlike the MNIST, the large format images produce interesting textures beyond the actual contours of the characters.
Samples:

Enlarged:
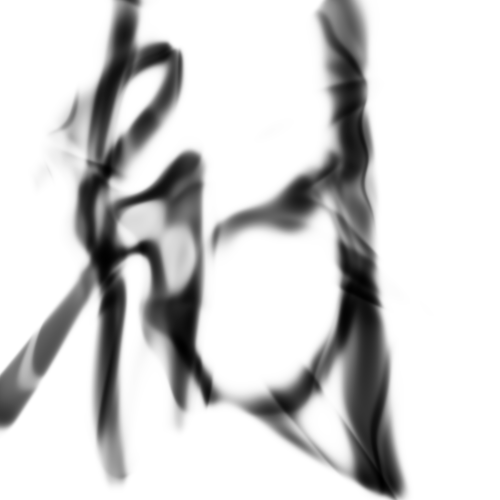

Interpolation:

Conclusion
It’s nice to finally have a CPPN model that trains properly, and for the most part avoids mode collapse, but the blurriness is not ideal for generating aesthetically pleasing images.


As GAN literature continues to expand at an astounding pace (see the Gan Zoo!), there’s still an amazing amount of potential to find new models, architectures, and designs that create pleasing and interesting art. Wasserstein distance is also only one metric out of many other new approaches, such as least squares (LS-GAN). There certainly will be more progress to be made, as researchers continue to refine this area of study.
References:
- https://arxiv.org/pdf/1701.04862.pdf
- https://www.alexirpan.com/2017/02/22/wasserstein-gan.html
- https://arxiv.org/pdf/1704.00028.pdf
- http://blog.otoro.net/2016/04/01/generating-large-images-from-latent-vectors/